


Nächste Seite: Der Webcrawl
Aufwärts: Vermessung des deutschen World-Wide-Web
Vorherige Seite: Das WWW als gerichtetes
Inhalt
Das Verfahren eines Webcrawl
Die Struktur des WWW wird von einer enormen Anzahl von
Autoren und deren persönlichen Neigungen bestimmt. Ebenso wie das
Erzeugen nehmen auch das Löschen und Ändern von Seiten Einfluß auf die
Form dieses Netzwerks. Insgesamt wächst das Netzwerk derzeit exponentiell
mit der Zeit [26]. Dieses dynamische Wachstum führt aber dazu, daß es
keinerlei ``Karte'' oder Regeln für die lokale Form des Netzwerks gibt.
Um dieses Netzwerk untersuchen zu können, wird jedoch genau dieses Abbild
benötigt. Wie können diese Informationen gewonnen werden ? Dieses
Problem stellt sich ebenfalls beim Suchen von Seiten mit bestimmten
Informationen im WWW und ist Gegenstand der Arbeit von
Suchmaschinen. Eine der ersten Suchmaschinen war der ``World Wide Web
Worm'' (WWWW) [35] mit einem Datenbestand von ca. 110000 Seiten.
Inzwischen sind Suchmaschinen zu einem unverzichtbaren Bestandteil des WWW
geworden und verwalten jeweils Datenbestände von bis zu einigen 100
Millionen Seiten. Die Seiten werden dabei mit Programmen (Crawler)
gesammelt, die ausgehend von einer Startseite alle Links dieser Seite
verfolgen, um zu neuen Seiten zu gelangen. Ausgehend von jeder dieser
neuen Seiten wiederholt sich dieser Vorgang. Dieses Vorgehen (Crawlen)
entspricht einer Breiten-Suche und ist das übliche Vorgehen von Suchmaschinen.
Allerdings wirft es eine große Anzahl an Problemen auf [22]: das
enorme Datenaufkommen durch die Seiteninhalte, der Speicherbedarf in
Datenbanken, die effektive Indizierung nach Inhalten seien hier exemplarisch
erwähnt. Damit die Crawler effektiv arbeiten und sich nicht in Schleifen
aus Verweisen verlaufen, muß stets bekannt sein, welche Seiten bereits
analysiert wurden. Das stellt sehr hohe Ansprüche an die Computer auf denen die
Crawler-Programme laufen und deren umgebende Hardware. Diese Probleme sind
jeweils der begrenzende Faktor und das Abbruchkriterium für einen Lauf der
Crawler - dem sogenannten ``Webcrawl''. Darüber hinaus ist das WWW einem
kontinuierlichem Wandel durch Änderungen unterworfen, so daß die Webcrawls
regelmäßig wiederholt werden müssen. Gegenwärtig sind alle Suchmaschinen
maximal in der Lage einen Bruchteil des WWW abzubilden [4]. Das führt dazu, daß
zunehmend spezialisierte Suchmaschinen entstehen, die gezielt
Informationen bestimmter Gebiete sammeln, um eine gute Aktualität zu gewährleisten.
Eine auf das deutsche WWW spezialisierte Suchmaschine ist
``Speedfind''3.1 der Freenet AG. Sie gehört
mit einem Datenbestand von ca.
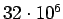 Dokumenten zu den kleineren
Suchmaschinen [36]. Um diesen
Datenbestand auf einem aktuellen Stand zu halten ist eine beachtliche
Rechnerkapazität kontinuierlich im Einsatz (Tab. 3.2).
Dokumenten zu den kleineren
Suchmaschinen [36]. Um diesen
Datenbestand auf einem aktuellen Stand zu halten ist eine beachtliche
Rechnerkapazität kontinuierlich im Einsatz (Tab. 3.2).
Die Freenet AG stellte freundlicherweise einen Abzug der Linkstruktur
dieses Datenbestandes zur Verfügung. Aus diesen Daten sind
dynamische Webseiten (PHP, CGI, Java, etc.) entfernt worden, da deren Inhalt von
besonderen Faktoren bestimmt wird. Der Inhalt variiert beispielsweise in Abhängigkeit
von der Tageszeit, dem Betrachter oder im Extremfall mit jedem Abruf.
Tabelle:
Hardwareausstattung der Suchmaschine ``Speedfind'' für
das Erfassen und Aktualisieren des Datenbestandes
|
Rechenleistung | 64 CPUs je 650 MHz, Rechenleistung etwa 41600 BogoMIPS. |
|
Festspeicher | 98 Festplatten mit einer Kapazität von rund 1.5 TB |
|
RAM | 8192 MB |
|
Nächste Seite: Der Webcrawl
Aufwärts: Vermessung des deutschen World-Wide-Web
Vorherige Seite: Das WWW als gerichtetes
Inhalt
Autor:Lutz-Ingo Mielsch